






A fast and feature-rich serverless alternative to Aurora provisioned instances
Table of contents
- What is RDS Aurora, what is RDS Aurora Serverless V2, and what happened to V1?
- Using Aurora Serverless V2 with AWS Lambda
- Combining auto-scaling with provisioned clusters
When you are using a serverless database like Aurora Serverless V2, chances are you are running your compute on AWS Lambda. This blog will illustrate what RDS Aurora serverless V2 is and how it scales in response to concurrent lambda connections. The content for this blog is based on re:Invent workshop DAT-310-R.
What is RDS Aurora, what is RDS Aurora Serverless V2, and what happened to V1?
AWS has various flavours of managed databases with their Relational Database Service (RDS), as shown in the picture below. Aurora is a database engine compatible with either MySQL or PostgreSQL, with some additional benefits. For example, the data inside your Aurora cluster is automatically replicated 6 times across three availability zones (so 3 or more data centres) to improve availability and reliability. This is different from other database engines, where storage is coupled directly to the database instance itself using an EBS volume. With Aurora, failure of the database instance does not affect the data in your database!

To access your data with Aurora, you can choose to either run an Aurora instance with fixed CPU and Memory, or run in Serverless mode where CPU and Memory is dynamically allocated. Despite its name, Aurora Serverless V1 is still a valid engine and serves different use-cases than V2.
The V1 engine can be fully stopped, meaning you only have to pay for any storage in your cluster during that time. When data is accessed, you have to wait for a few seconds for the engine to start again. Also, scaling up and down takes a bit of time. It's great for infrequently accessed applications that can tolerate some latency every now and then, like reporting services that run once per day. Also, the V1 engine has a data API, enabling developers to securely connect to their database using AWS IAM credentials over the public internet. The benefit of this is that it's much easier to connect to your cluster in a secure way with AWS Lambda.
On the other hand, the V2 engine cannot be fully stopped and runs at a minimum of 0.5 Aurora Capacity Units (roughly equivalent to 1 GB memory and according CPU). This means it's costing roughly $45 per month when your application is idling. It also does not have the data API feature (yet?). However, it's much faster at scaling and handling concurrent connections than V1. How fast? Let's find out!
Using Aurora Serverless V2 with AWS Lambda
Step 1: Connecting aurora serverless V2 to Lambda
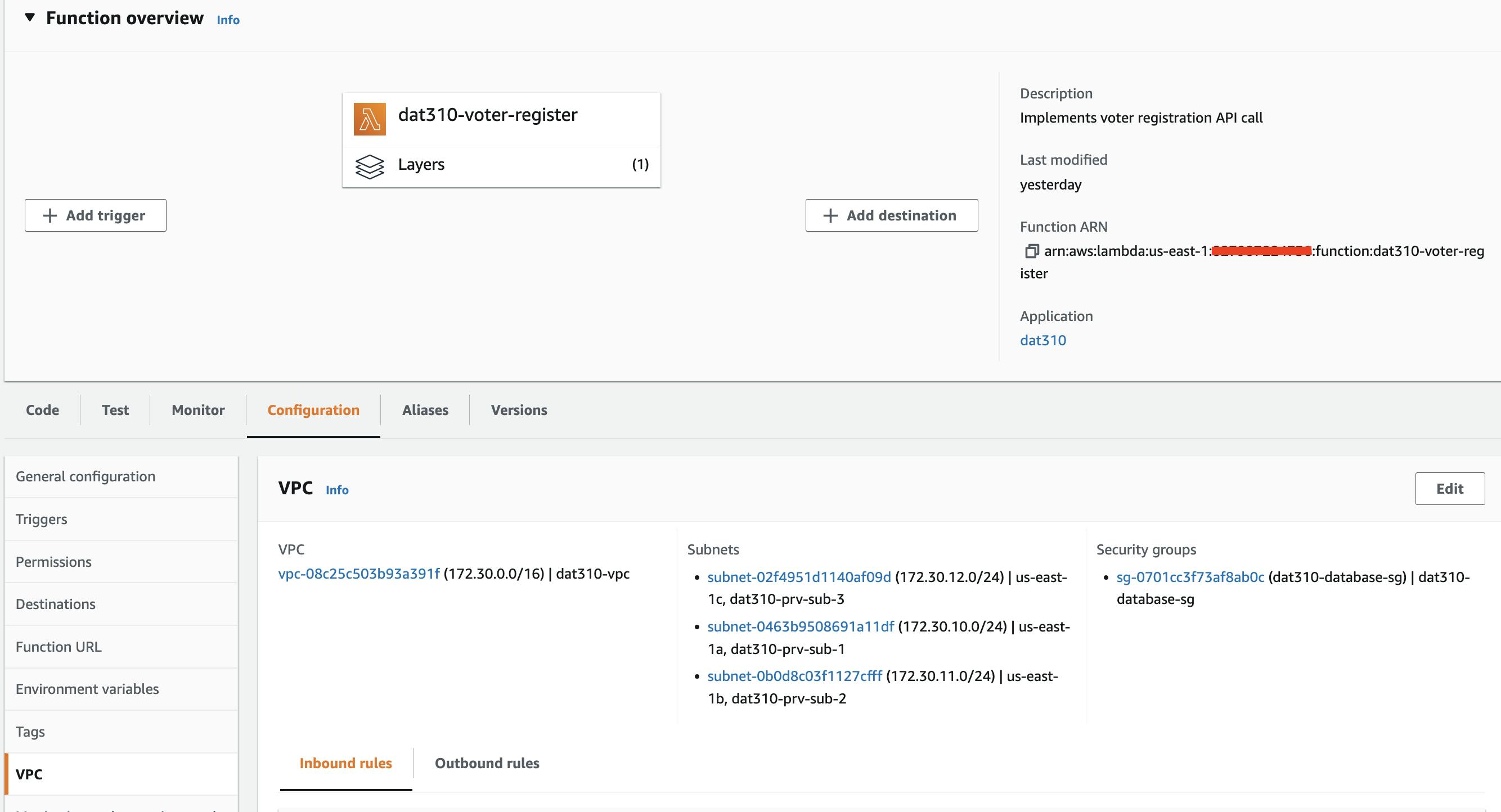
As mentioned, Aurora Serverless V2 has a caveat when working together with Lambda: Aurora Serverless V2 is deployed in a virtual PRIVATE cloud (VPC). AWS Lambda is, by default, not running in a private cloud. This means that when using lambda default settings, you don't have connectivity to this database instance.
You can fix that by making sure lambda is running INSIDE the same VPC as your Aurora serverless cluster. You can verify the lambda VPC settings in the lambda service page like shown below. Also make sure the security group of the Aurora serverless V2 cluster allows traffic from the security group attached to the lambda.
Step 2: Testing the scaling functionality
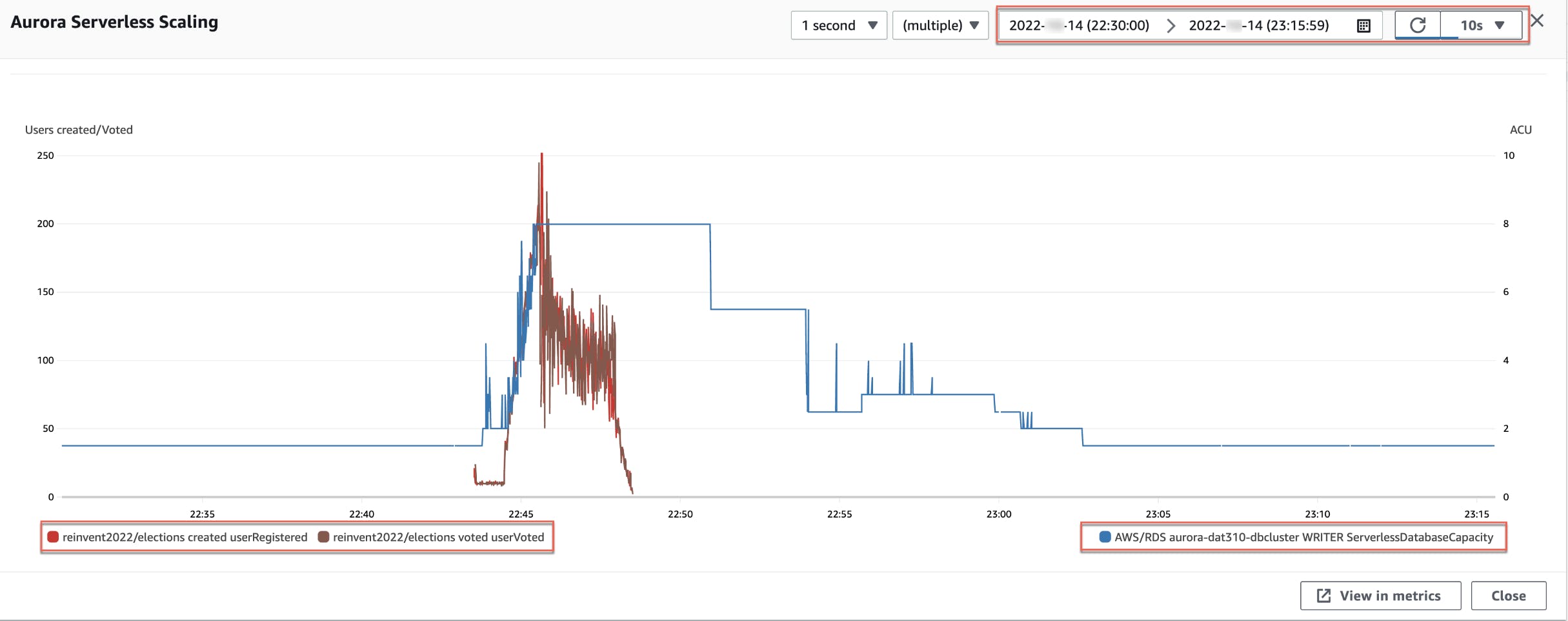
The AWS documentation state that it has Instant scaling to hundreds-of-thousands of transactions per second. Pretty impressive! To see how fast Aurora Serverless adapted to an increase in load, a custom script was used to invoke many lambda's concurrently. Within one minute, load was ramping up a few hundred concurrent requests per second (red line below). As shown in the diagram, Aurora Serverless V2 immediately started to scale. Every second, Aurora Serverless V2 checked if additional CPU capacity is required and scaled up when needed.
This shows us that Aurora Serverless V2 scaling performance is actually very impressive and orders of magnitude faster than V1. I'm excited to use it for future projects! If only it had the data API as well...
Combining auto-scaling with provisioned clusters
It is noteworthy that within an Aurora cluster, you can combine the serverless V2 version with provisioned instances. These will get different endpoints, so if you write your application correctly you can make use of this. For example, if you have very heavy queries that run not that often, use the Serverless endpoint for those workloads! It can save you costs, because you can then use a smaller provisioned instance for your continuously running, stable processes!
--
This blog also appeared on cloudengineer.hashnode.dev





